Understanding Gradient Descent Algorithm and the Maths Behind It
- by user1
- 20 March, 2022
This article was published as a part of the Data Science Blogathon
This article throws light on how the Gradient Descent algorithm’s core formula is derived which will further help in better understanding of the Gradient Descent Algorithm. First, we will understand what is Gradient Descent algorithm is in brief.
A Brief idea of Gradient Descent Algorithm
Imagine you are standing at a grassy park on a hill. Suppose you want to come down at the base of the hill as quickly as possible. So what would you do?
You will look around everywhere and think if you were to take baby steps in some direction to go downhill as quickly as possible then in what direction you will take those baby steps to walk down as rapidly as possible? You will find the best direction and take one step and land on a new point on the hill.
Again you will look around to find the direction to take the next baby step in order to go downhill. If you take that step, you will land upon another point on the hill.
This way thinking about what direction to go and take the step will be continued until you reach downhill which is the global minimum.
The Core of Gradient Descent Optimisation Algorithm
Gradient Descent is an Iterative Solver. The Iterative solver does not give the exact solution. Not in all cases, the objective function is solvable.
In such cases, the iterative solvers are used to get the approximate solution as the purpose is to minimize the objective function.
The basic principle of gradient descent is to choose the step size (also called as learning rate) appropriately so that we can get close to the exact solution. So learning rate basically controls how big a step we take downhill.
The gradient descent update rule is given as follows :

Image Source: Created by Author
Gradient Descent can be summarized using the formula,
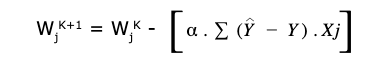
Image Source: Created by Author
We repeatedly calculate this until convergence.
Let’s see how we got this formula.
Starting with a simple Machine Learning Model
We will take an example of a linear regression model.
Suppose you have a set of data points and a line in a 2-D space. If you plot these points and try to draw a line passing through these points, it will look like as follows :
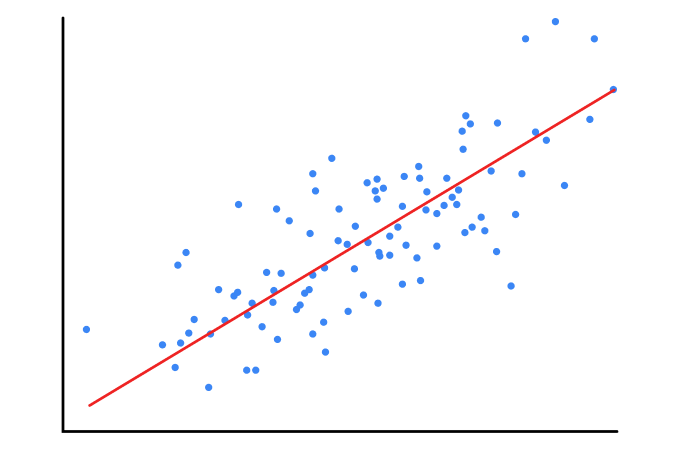
Image Source: https://backlog.com/blog/gradient-descent-linear-regression-using-golang/
The equation of a line is given as Y = mX + b where m is the slope of the line and b is the intercept on the Y-axis.
When you try to make a prediction, you take a data input X and make a guess.
Let’s call that guess as

Image Source: Created by Author
You already know Y. So, Y is the correct data that goes with X.
Your machine learning model makes a prediction.

Image Source: Created by Author
So, Error is the difference between the two, that is,
the predicted value – correct value
It relates to the idea of cost/loss function.
Let’s see what does cost/loss function does and why do we need it.
Concept of Cost / Loss Function
The Loss function computes the error for a single training example.
The Cost function is the average of the loss function for all the training examples.
Here, both the terms are used interchangeably.
If you want to evaluate how your ML algorithm is performing, for a large data set what we do is take the sum of all the errors.
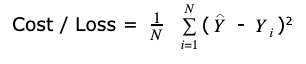
Image Source: Created by Author
This is the total error for the particular model, being m and b values that describe that line.
Our goal is to minimize that loss. We want the lowest error. That means we want the lowest m and b values to get the lowest error.
So, the above cost function is equivalent to Y = f(x) = X2
If you graph Y = X2 on the Cartesian Coordinate system, it will look as follows:
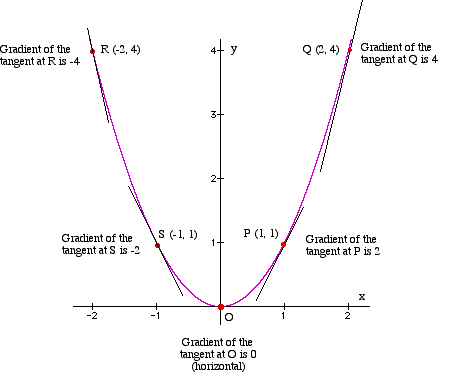
Image Source: http://bestmaths.net/online/index.php/year-levels/year-11/year-11-topics/gradient-curve/
Suppose we are considering Q as the current data point. We have to find the minima which is at point O. Then there are 2 things that we need
- Which direction to go (Direction of update)
- How big step to take (Amount of update )
The way to find minima is by taking a derivative (also known as gradient).
The gradient of a curve at any point is given by the gradient of the tangent at that point.
Also, the gradient of a curve is different at each point on the curve.
See the above diagram carefully. Gradients are different at all the points P, Q, R, S, and O.
So the most common ways to look at derivatives are:
- The Slope of the tangent line to the graph of the function
- Rate of change of the function
Here the goal is to find a line that has the smallest error.
It means minimizing a function means actually finding the X value that produces the lowest Y.
So, this idea of being able to compute the slope(derivative) of this function tells us how to search and find the minima.
Parameters m and b with a slight change can be written as:

Image Source: Created by Author
So, we want to know what is the way we can change the value of m in y = mx + b in order to make the error lesser. Hence, the next step is to find the m and b values with the lowest error. It can be done by finding the derivative (gradient) of this cost/loss function to know which way to move.
Here, we will be using the following 2 rules of calculus to find the derivative:
Power Rule:
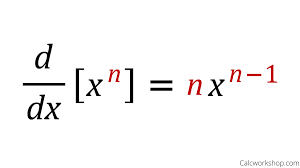
Chain Rule:

Let’s say J(m,b) is the Cost / Loss function in m and b.

Let us assume that we are looking at one error at a time. So we will get rid of the summation sign.
J(m,b) = Error2
Differentiating J with respect to m and applying Power rule and Chain Rule
We are applying the chain rule because J is a function of Error and Error is a function of m and b.

Similarly, differentiating J with respect to b
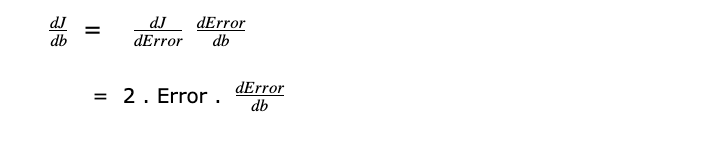
As discussed above,
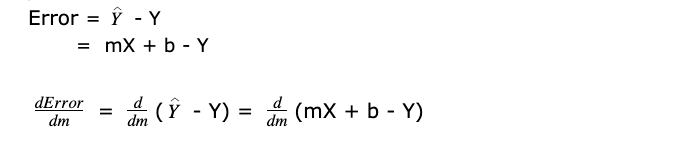
X is input data, b is constant and Y is output.
Derivative of constant is Zero because constant does not change and derivative describes how something changes. Hence derivatives of b and Y are zero.
According to the power rule,

We can get rid of 2 as it just tells how big or small the learning rate is. So it’s not significant.
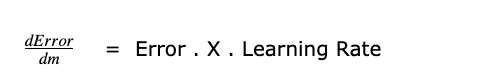
(Error . X) decides direction as slope/derivative contains the direction information.
Learning rate decides step size/amount of update.
Differentiating Error with respect to b
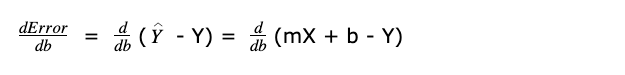
X is input data, m is constant and Y is output. As discussed earlier,

According to the update rule,

EndNote
The purpose of this article is to simplify the mathematical concepts, mainly derivatives and calculus which are required to understand the gradient descent algorithm.
The media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion.
Size: Unknown Price: Free Author: Nasima Tamboli Data source: https://www.analyticsvidhya.com/