



This article was published as a part of the Data Science Blogathon
Introduction
The main goal of machine learning is to train models and predict outcomes that can be used by applications. In Azure Machine Learning, we use scripts to train models using machine learning frameworks like Scikit-Learn, Tensorflow, PyTorch, SparkML, and others. In this guide, we will go in-depth about Azure Machine Learning, its capabilities, the azure ecosystem that supports Machine learning activities, and the multiple ways in which we train and build models.
What is Azure Machine Learning? It’s a cloud-based, fully orchestrated module, that helps us operationalize the various machine learning tasks and the iterative processes efficiently while leveraging the enormous computing power provided by Microsoft Azure
Advantages of Azure Machine Learning
Let’s look at some of the advantages of using Azure ML
- For most users, setting up all the infrastructure to efficiently train machine learning models can be overwhelming. With Azure ML, we can focus on data science and solving problems, and azure takes care of the infrastructure setup and license requirements
- Azure, or for that matter, any of the cloud providers are pay-as-you-go. If used diligently, like for instance, carefully turning off the running instance when not in use, it can be a highly cost-efficient model.
- One feature that I find handly is that Azure allows us to publish our trained model as a web service and consume it in applications
- A wide range of algorithms is supported which we can easily configure.
Key capabilities of Azure Machine Learning
Azure has built some useful features in its Machine learning offering that makes things easier for a wider audience. You would find these features indispensable, especially if you are not used to setting up the machine learning workflow and environment manually.


Some of these features are:
- On-demand compute that you can customize based on the workload
- Data ingestion engine which I found to be extensive in terms of the sources it accepts.
- Workflow orchestration for machine learning is incredibly simple with azure.
- Machine Learning model management – if you like evaluating multiple models before selecting the final one, azure machine learning has dedicated capabilities to manage this.
- Metrics & logs of all the model training activities and services we utilize are readily available on the platform.
- Model deployment – With azure ML, you can deploy your model in real-time
Azure Machine Learning studio services
Microsoft has designed the studio as a web-based tool for managing the machine learning workspace. Studio services are graphics-based tools that enable us to automate ML as well as abstract the model development to a No-Code level using drag and drop features. In addition to building a custom model in an expert mode, I will cover these two approaches in detail in the upcoming section of this guide. How can you access the Azure Machine learning studio? You need to go to https://ml.azure.com from your browser and sign in using your Azure subscription.
Now that we have covered the key capabilities that come with Azure ML, let’s look at the ecosystem that Azure offers around machine learning
Azure Machine Learning ecosystem
Various services work along with Azure ML to integrate the whole ecosystem around data and analytics. Here are the key ones:
Managing big data
As we know, machine learning is about creating predictive models by utilizing the available data. In today’s world, this data can be voluminous and we need dedicated tools to ingest this data for building our models. Azure ML offers multiple services like Azure SQL Database, Azure Cosmos DB, Azure Data lake to help us achieve this task. In addition, we can benefit from services like Apache Spark engines in Azure HDInsight and Databricks to transfer and transform big data.
Azure services for web, mobile, and IoT
Services like Azure App Services, Azure IoT Edge are designed just for this and we can leverage these from inside of Azure ML framework.
Container-based deployments
To build your machine learning models, package and deploy them, container-based deployment is the right approach. This is part of modern software deployment methodologies where we prefer a microservices approach. The idea is to deploy software in small logical units. This goes well with the DevOps approach and moves away from the traditional monolithic approach to software development. With Azure, we do this using services like Azure Kubernetes Services and Azure Container Services.
Talking about DevOps, let’s look at how Azure Machine learning enables ML Ops
MLOps – ML Operationalization
As machine learning becomes mainstream, there is an increased focus on integrating the ML activities like model training, deployment, and maintenance in the larger framework of developing and delivering software. The set of activities that help us achieve this is known as MLOps. This merges with the DevOps activities of the overall software engineering.
What is DevOps? Well, DevOps is a set of practices for driving efficiency in developing software at an enterprise scale. This encompasses all the systems and processes that enhance team collaboration, leverage process automation to bring about efficiencies.
This is a paradigm shift in the way ML would integrate within the larger software development framework. Traditionally, ML experts would build models and it would be left to software developers and system administrators to integrate these models into the overall application. Using DevOps principles in Machine learning is increasingly enhancing the overall effectiveness of building an overall solution. Azure Machine Learning has capabilities to integrate with overall DevOps systems like Azure DevOps and GitHub integration.
Building Machine Learning Models in Azure
Now that we have covered the overall architecture of Azure Machine Learning, let’s deep-dive into building machine learning models inside Azure Machine Learning.
As we know, model building is an iterative process. In this guide, I will cover three approaches we can use to build machine learning applications using data:
Approach #1: Expert mode – As Data Scientists, when we want to use our knowledge of programming in languages like Python and associated libraries like PyTorch, Scikit-Learn to train machine learning models, Azure offers this flexibility to build models in our unique, customized way. Here, we decide the model we will use, the computing power, the dependencies we want to configure.
Approach #2: Azure ML studio-based Automated Machine learning – This is useful for users where the aim is not to get into the nitty-gritty of building a model but to utilize the power of having a model in place. We use Azure’s machine learning studio to evaluate multiple models, configured by Azure, and return the best performing one. The heavy lifting around statistics and mathematics is taken care of by Azure Machine Learning studio.
Approach #3: Designer mode – This is a graphical utility and works along the lines of the No-code paradigm that is increasingly becoming popular. Users who wish to utilize machine learning as part of a larger application. We want to oversee the automated DevOps process, re-train the model and check the performance of the overall application.
The dataset for this guide
To demonstrate the model building in Approach #1 and #2, I will use the diabetes dataset. Here’s the GitHub link to the dataset. The goal of this dataset is to determine if a person would be diabetic or not.


Approach 1 – Expert mode – Custom settings and building a model of our choice in
Let’s begin with the first approach, where we determine the model to be used. Since the outcome is a prediction around the likelihood of getting diabetes, a categorical measure, I am using a Logistic regression model for this prediction
Train Machine Learning Model using Python
Here’s how you train your machine learning model using Python within the Azure ML framework. I have explained this approach in 8 steps:
Step 1: Create Azure Workspace
Workspace is a centralized place to manage resources required for training a model. We can use workspaces to group resources based on projects, deployment environments like testing and production, based on organization unit, etc. Workspaces are defined within a resource group in Azure.
The assets in a workspace include computing targets, data for model training, Notebooks, Experiments, Models, Pipelines, etc.
When we create an Azure workspace it also creates the following
- Storage account to store data for model training
- Applications Insights to monitor predictive services
- Azure Key Vault to manage credentials
To access these resources in Azure Workspace, users need to authenticate using the Azure Active directory
Below are the steps to create an Azure Workspace:
Create a Machine Learning Resource from Azure Portal


2. Once the resource instance is created, provide the requested information like Workspace Name, Region, Storage account, Application Insights and create the workspace.


Step 2: Create Compute Instance
Compute instances are online computed resources that already have a development environment installed to write and run code in Python. We can have multiple compute instances in a workspace.
Based on our requirement we can select a compute instance with desired CPU, GPU, RAM and Storage.
Below are the steps to create a compute instance
- From the left navigation, select on new compute instance

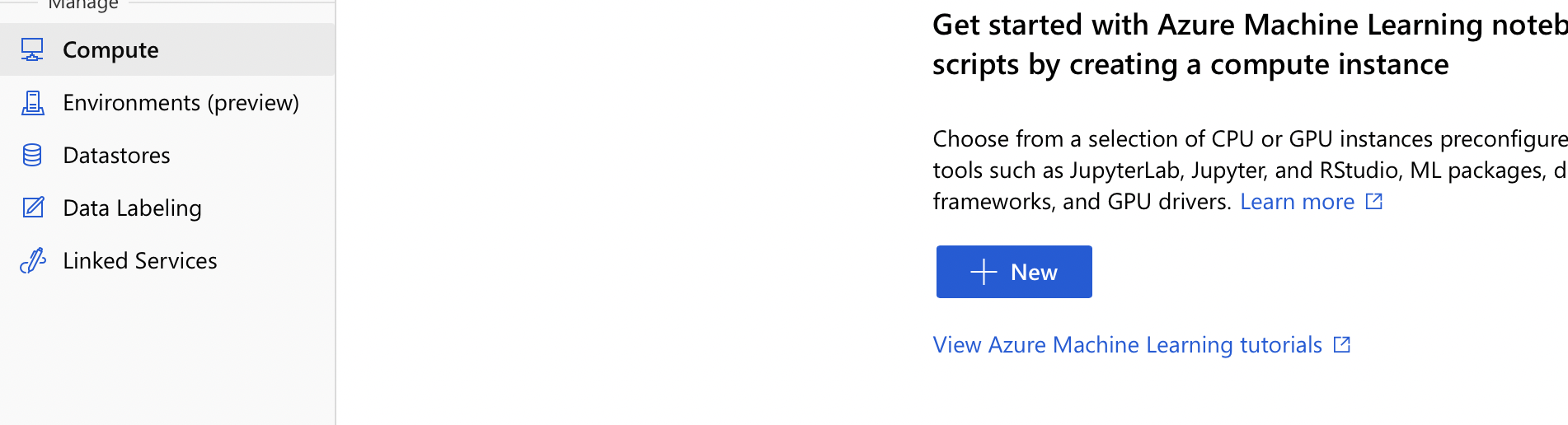
2. Provide Compute Instance Name, Select the required VM and create the compute instance


We can also create compute clusters where we can autoscale the CPU/GPU compute nodes in the cloud
Step 3: Create DataSet
1. Click on DataSet and create a new DataSet. I have uploaded the data using from local files option


2. Provide DataSet name and upload the file.


Step 4: Create an Azure Notebook and Connect to Workspace
1. Go to Machine Learning Studio and click on Create New Notebook


2. Create a new Notebook
3. Import the azureml-core package, a Python package that enables us to connect and write code that uses resources in the workspace and
import azureml.core from azureml.core import Workspace ws = Workspace.from_config()
Step 5: Create a Training Script to train the model
In this step, we will be creating a script to train the model and save the script as a .py file in our folder using the below command:
%%writefile $training_folder/diabetes_training.py
1. Let’s create a folder to save all the python scripts. We will be saving the Training scripts in a folder named diabetes-training
training_folder = 'diabetes-training' os.makedirs(training_folder, exist_ok=True)


2. Get the path of the CSV file which we uploaded as a Dataset. Data files can be accessed using Datastores. Datastores are used to store connection information to Azure storage services.
In my case, the datastore name is ‘workspaceblobstorage’. We can go to Home> Datasets > Registered DataSets to view all the data sources registered.


datastore_name = 'workspaceblobstorage' datastore_paths = [(datastore_name, 'diabetes.csv')]
3. Get the Run context. A run represents a single trial for an experiment. We can have multiple Runs in a single experiment.
Using Run we can monitor the trial, log metrics and store the output of the trial, and then analyze results generated.
run = Run.get_context()
4. Read the dataset using the Pandas library
diabetes = pd.read_csv(Dataset.Tabular.from_delimited_files(path=datastore_paths))
5. Create the datasets X and Y. X has the feature variables and Y has the output variable
X, y = diabetes[['Pregnancies','PlasmaGlucose','DiastolicBloodPressure','TricepsThickness','SerumInsulin','BMI','DiabetesPedigree','Age']].values, diabetes['Diabetic'].values
6. Split the dataset into train and test and use a logistic regression model as we are trying to solve a classification problem – if a person has diabetes or not.
Here we have split the train and test data in a 70:30 ratio.
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=0)
# Set regularization hyperparameter
reg = 0.01
# Train a logistic regression model
run.log('Regularization Rate', np.float(reg))
model = LogisticRegression(C=1/reg, solver="liblinear").fit(X_train, y_train)
7. Next we calculate the accuracy and AUC of the model to evaluate our model
# calculate accuracy
y_pred = model.predict(X_test)
acc = np.average(y_pred == y_test)
print('Accuracy:', acc)
run.log('Accuracy', np.float(acc))
# calculate AUC
y_score = model.predict_proba(X_test)
auc = roc_auc_score(y_test,y_score[:,1])
print('AUC: ' + str(auc))
run.log('AUC', np.float(auc))
8. Save the trained model to the desired folder. In this example, we are saving the model to the output folder
# Save the trained model in the outputs folder
os.makedirs('outputs', exist_ok=True)
joblib.dump(value=model, filename='outputs/diabetes_model.pkl')
run.complete()
In this step, we have just written a script to train the model and stored it in a folder. We have not executed the script yet.
Step 6: Run the training Script as an Experiment
An experiment is a collection of trials that represent multiple model runs. We can run experiments with different data, code, and settings too.
The experiment is represented by Experiment Class and each trial in an experiment is represented by Run Class
1. We create a Python environment to run the experiment.
env = Environment.from_conda_specification("experiment_env", "environment.yml")
Where environment.yml contains the environment specifications
2. Next, we create a ScriptRunConfig which packages together information to submit a run like Script, compute targets, environments etc.
script_config = ScriptRunConfig(source_directory=training_folder,
script='diabetes_training.py',
environment=env)
3. Next, we submit the Experiment run and pass the ScriptConfig details
experiment_name = 'train-diabetes'
experiment = Experiment(workspace=ws, name=experiment_name) run = experiment.submit(config=script_config)
4. Then we run the Experiment run and wait for it to complete.
RunDetails(run).show() run.wait_for_completion()
Step 7: Retrieve the metrics and output of the run object and print it in Notebook
We can use the get_metric method of the run class to print the metrics like Regularization rate, AUC, Accuracy, etc
metrics = run.get_metrics()
for key in metrics.keys():
print(key, metrics.get(key))


Step 8: Register the trained model
In Step 5 we saved the model as a pkl file. Now we will register the model in the workspace so that we can track the model versions.
# Register the model
run.register_model(model_path='outputs/diabetes_model.pkl', model_name='diabetes_model',
tags={'Training context':'Script'},
properties={'AUC': run.get_metrics()['AUC'], 'Accuracy': run.get_metrics()['Accuracy']})
Once we have trained the model and registered it, we can see the output of each run from the Experiment in the left navigation

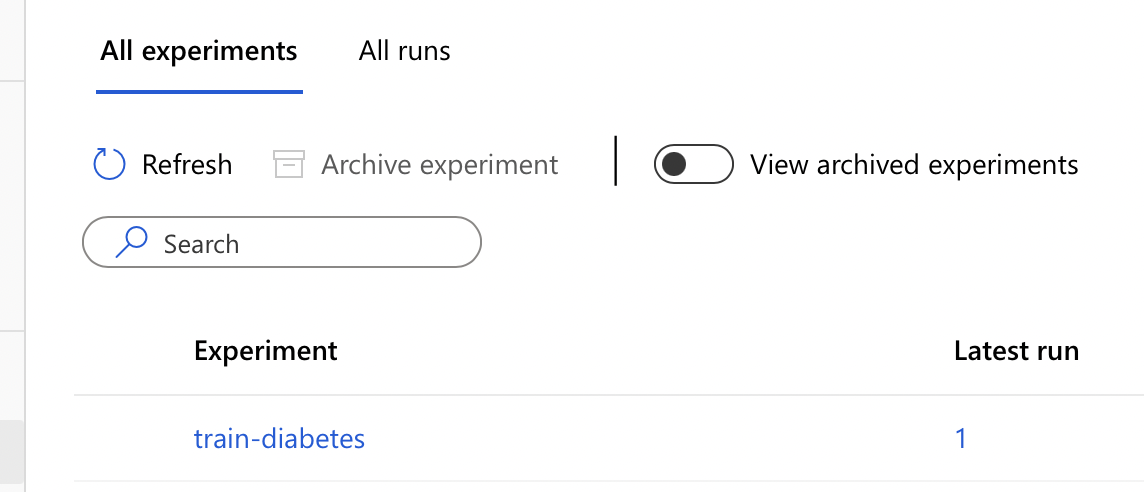
We can see the various runs when we click on the experiment name and their respective status


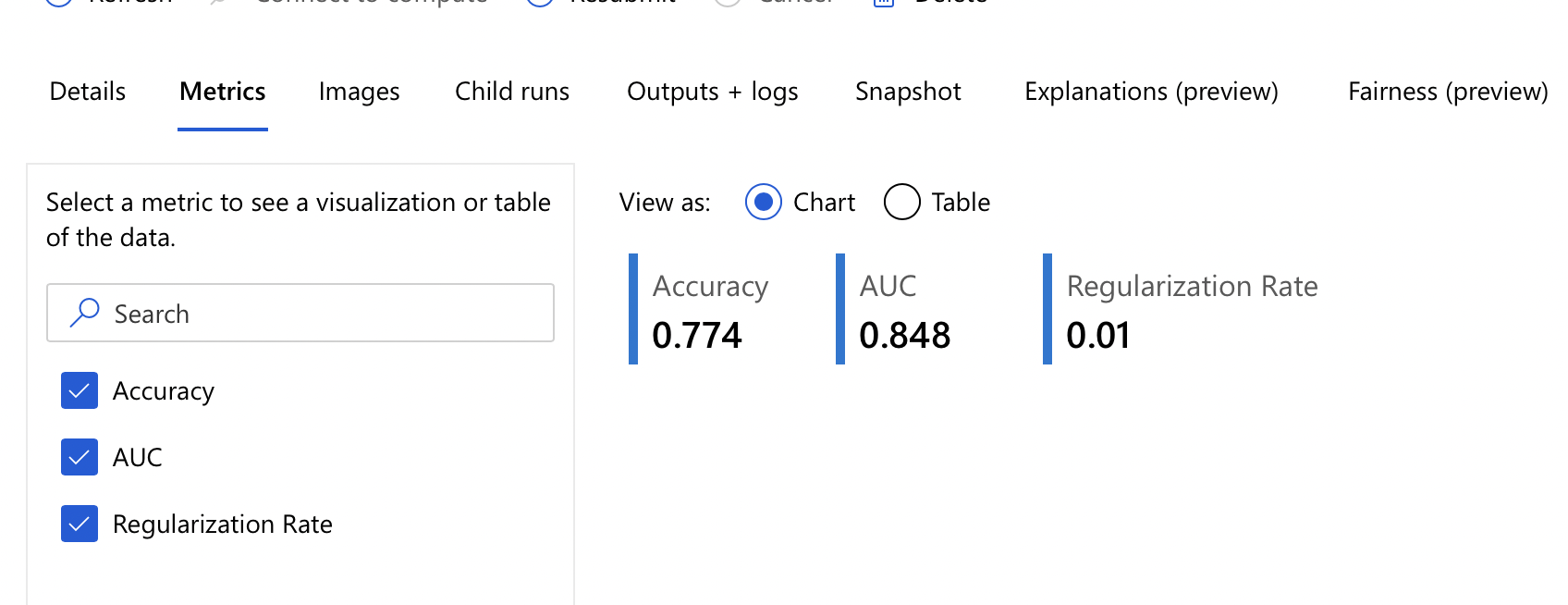
For each run, we can see associated metrics, outputs, logs etc. In this particular algorithm, the model has an accuracy of 0.774 and the area under the curve is 0.848

Approach II – Automated Machine Learning using Azure Machine Learning Studio
Given the iterative nature of building machine learning models, parallel processing of multiple models can save time and also help identify the best model for a particular use case. With the compute power that comes with Azure, optimizing algorithms for the best outcomes is remarkably easy in the Azure Machine Learning Studio environment. Studio automation takes away the need for all the manual trial and error iterations that come with building a model.
It is important to know that the Azure Machine learning studio supports only supervised machine learning models where we have training data and known labels. These models are:
- Classification models where we predict categories
- Regression models where we are working with numerical data and finding the best-fit equation
- Time series forecasting where we have dates data encoded and we try to forecast, say, future sales for a store.
Identifying the best performing model
How does the Azure ML studio identify the best-performing model? We can specify the metrics for the same. Here’s how we can configure the experiments in Azure ML studio:
- The primary metric – This is the metric for which you want to optimize the model. For instance, you can use accuracy as a primary metric. Here’s the table of all the metrics you can use as the primary metric.
Primary Metrics for Automated ML studio

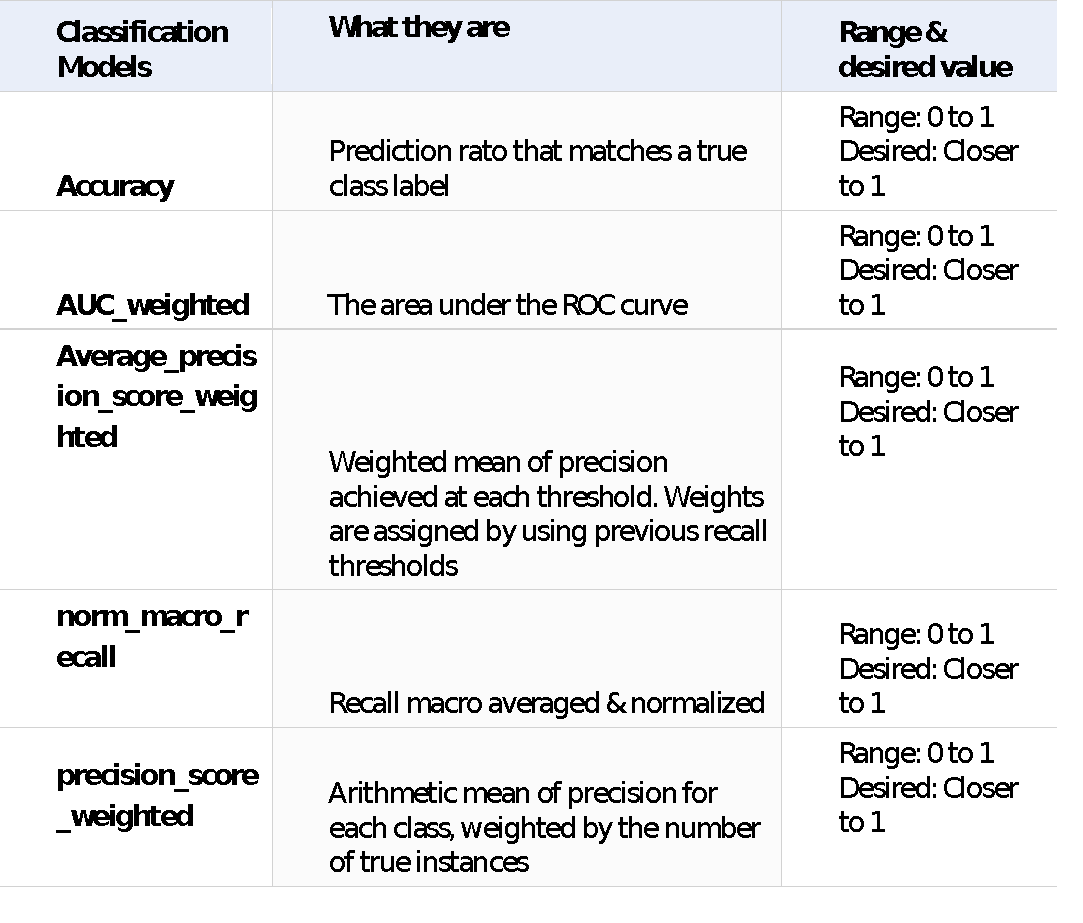
Figure: Primary metrics for Classification model

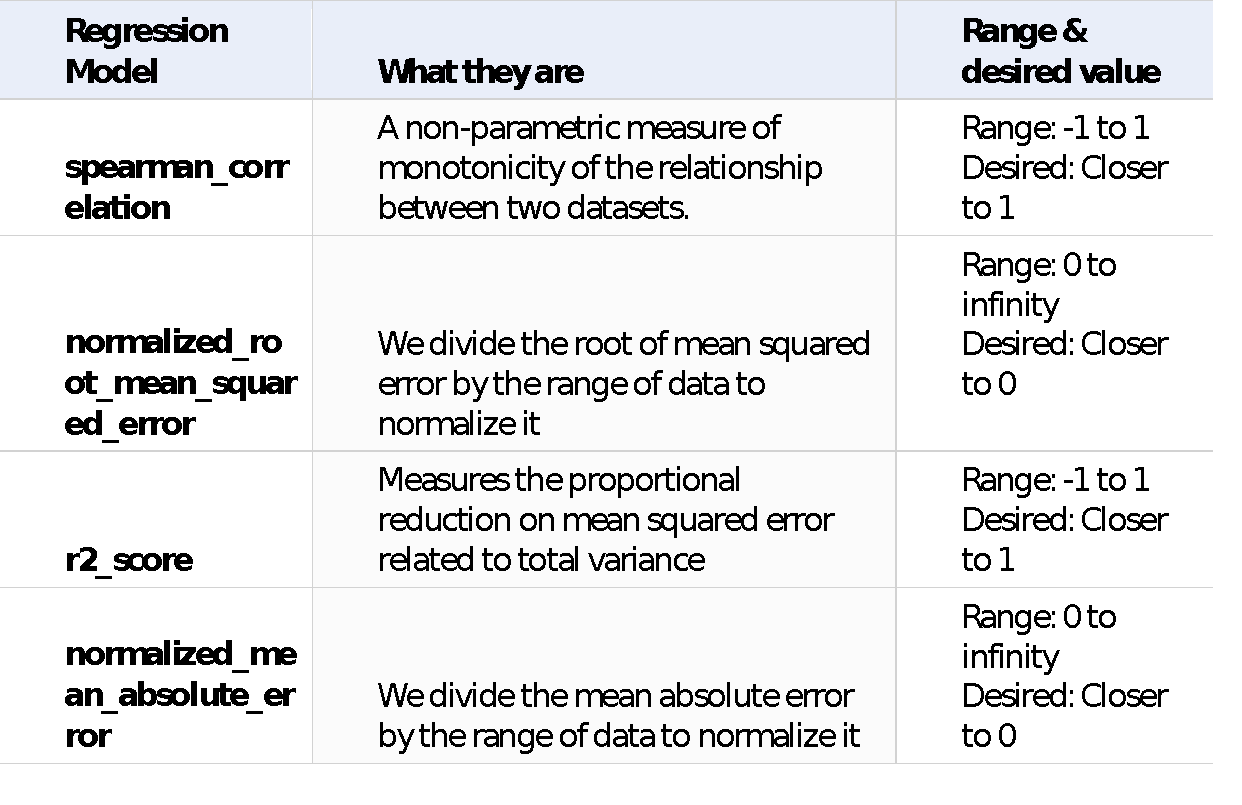
Figure: Primary metrics for a Regression model


Figure: Primary metrics for Time series forecasting model
Other metrics we can configure in the studio
- Explainability of AI – This helps us generate feature importance explanations for the best model identified
- Discard algorithms – These are algorithms you can discard upfront and the automated engine will not consider these. This helps save cloud costs.
- Exit criteria: As the machine learning operations are automated, you need to set the stop parameters for the experiment and the maximum amount of time or specific metric threshold is triggered.
- Data split for validation: You can configure how you want to split the dataset between training data and test data that you can use to evaluate.
- Parallel processing: One of the biggest time-saving features of Azure ML is the ability to run and evaluate multiple algorithms in parallel. You can configure these settings.
Data processing capabilities of Azure Machine Learning Studio
Everything you do in expert mode, you can also configure in this automated mode. This includes capabilities like imputing missing values, encoding categorical features, balancing data by normalizing and scaling the features, dropping high-cardinality features that do not help in prediction. You can also derive time-series features by extracting day, month, and year from the date field.
Key steps to run an automated machine learning algorithm
Step 1: Specify the dataset with labels to train the data. I have used the same diabetes dataset and created a new automated ML run.
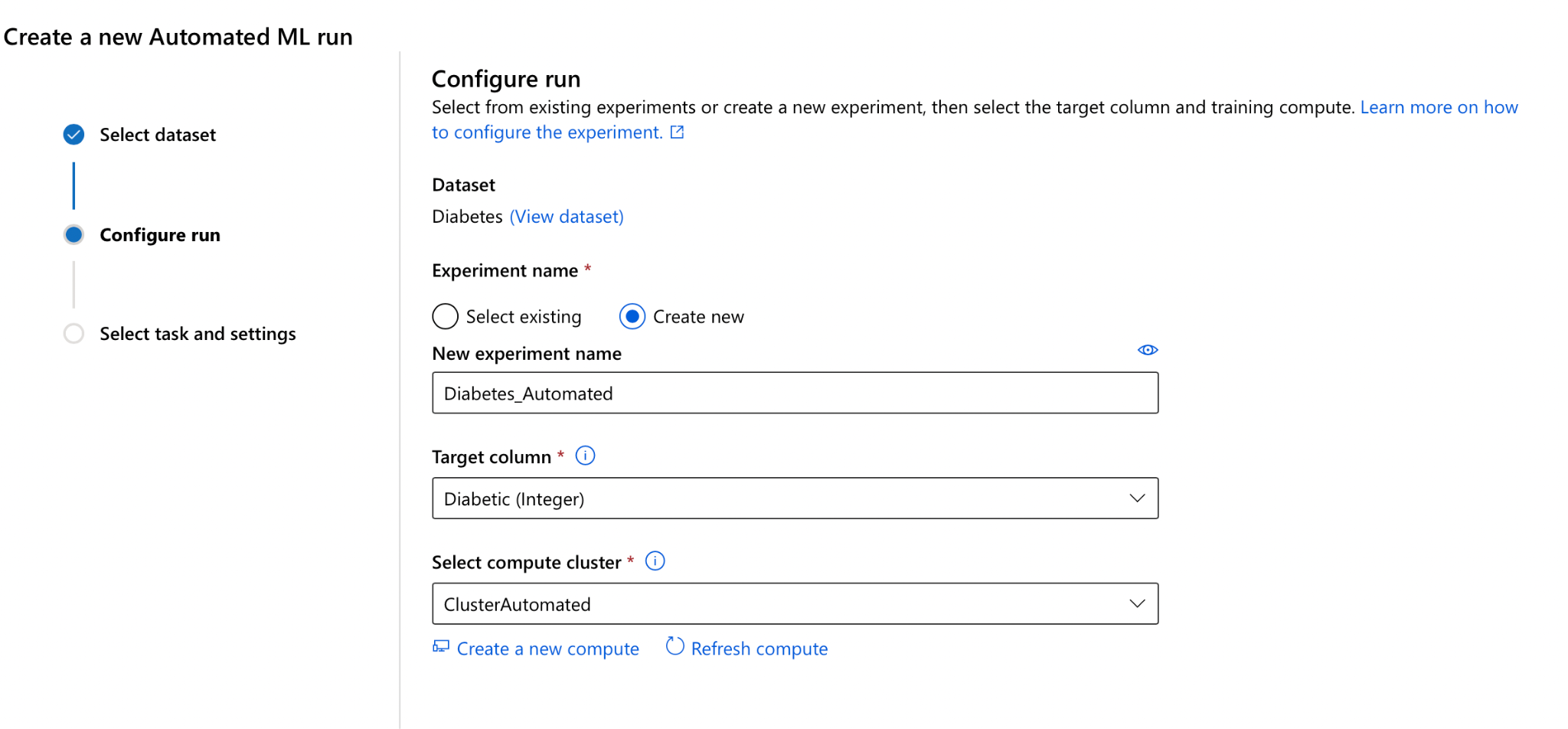
Step 2: Configure the automated machine learning run – name, target label and the compute target on which to run the experiment.

Step 3: Select the algorithm and settings to apply – classification, regression, or time-series, configuration settings, and feature settings

Step 4: Review the best model generated

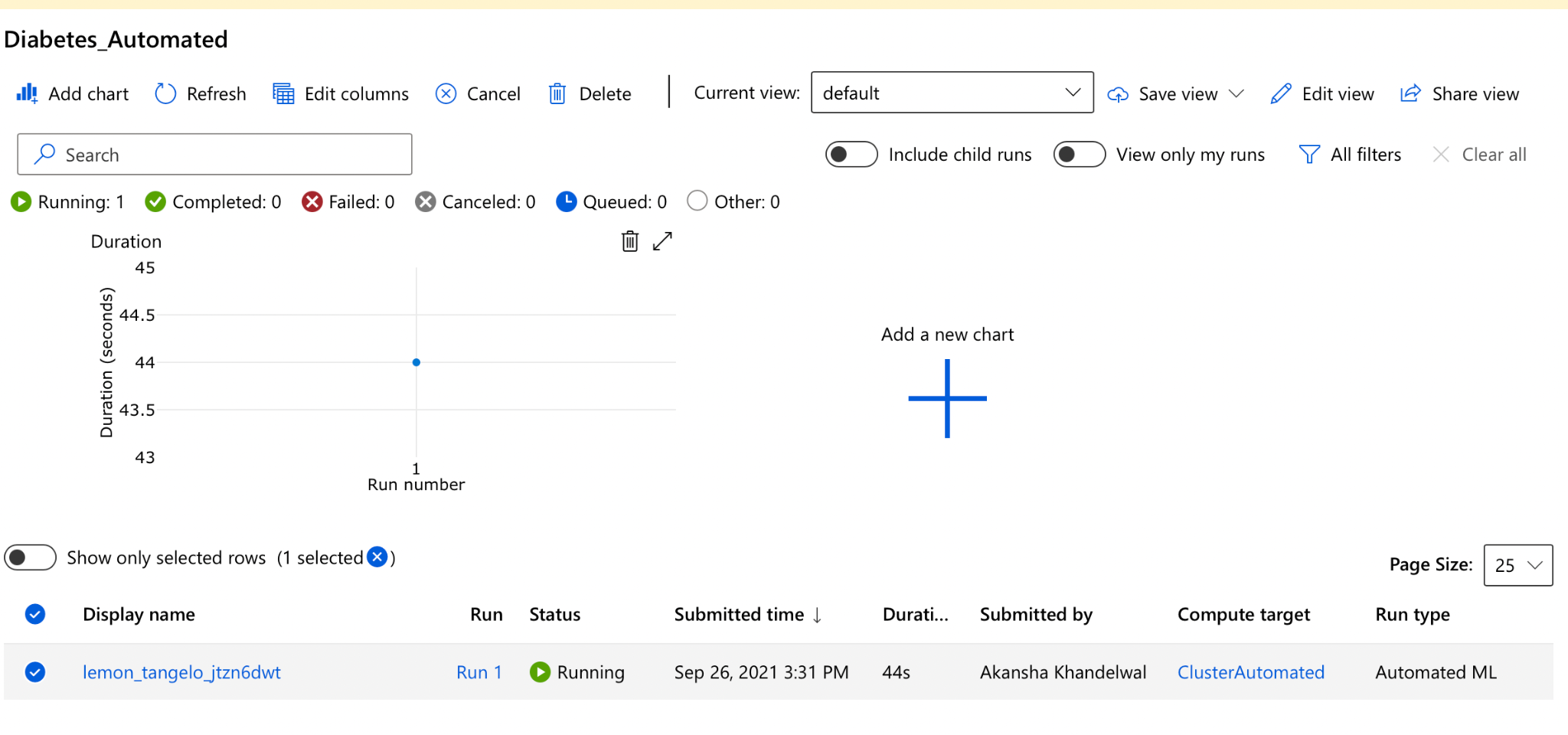
When we click on the experiment, we can see that there were multiple runs for different types of algorithms to identify which model would work well.


We can see that RandomForest had an accuracy level of 0.88, XGBoostClassifier had an accuracy level of 0.87.
Approach III – Training Model using Azure Machine Learning Designer
As we discussed, Azure Machine Learning Designer provides a graphical environment for creating machine learning models. Further, we can publish the models as services that are then used by the overall software development process.
Here is how you can build a model in Machine Learning Designer
Create a Training Pipeline
We define a dataflow for training a machine learning model, using drag and drop features. This designed workflow looks like a pipeline and is called a pipeline as evident in the picture below.
What does the training pipeline consist of? We design all the steps required before we build a model like data ingestion and feature engineering. In the designer interface, we can execute each of these steps independently. The pipeline manages the flow of execution.
As you might have noticed, we have not used any lines of code to accomplish these tasks. This is the key feature of the designer mode. As you would notice from the left column of the picture below, the designer includes a wide range of pre-defined modules for data ingestion, feature selection and engineering, model training, and validation. While Azure has designed this as a no-code environment, it has left room for adding custom scripts, if you so desire. We can add custom Python, R, and SQL logic to a data flow.
Training Pipeline
Step 1: Process the data, normalize the features using drag and drop.

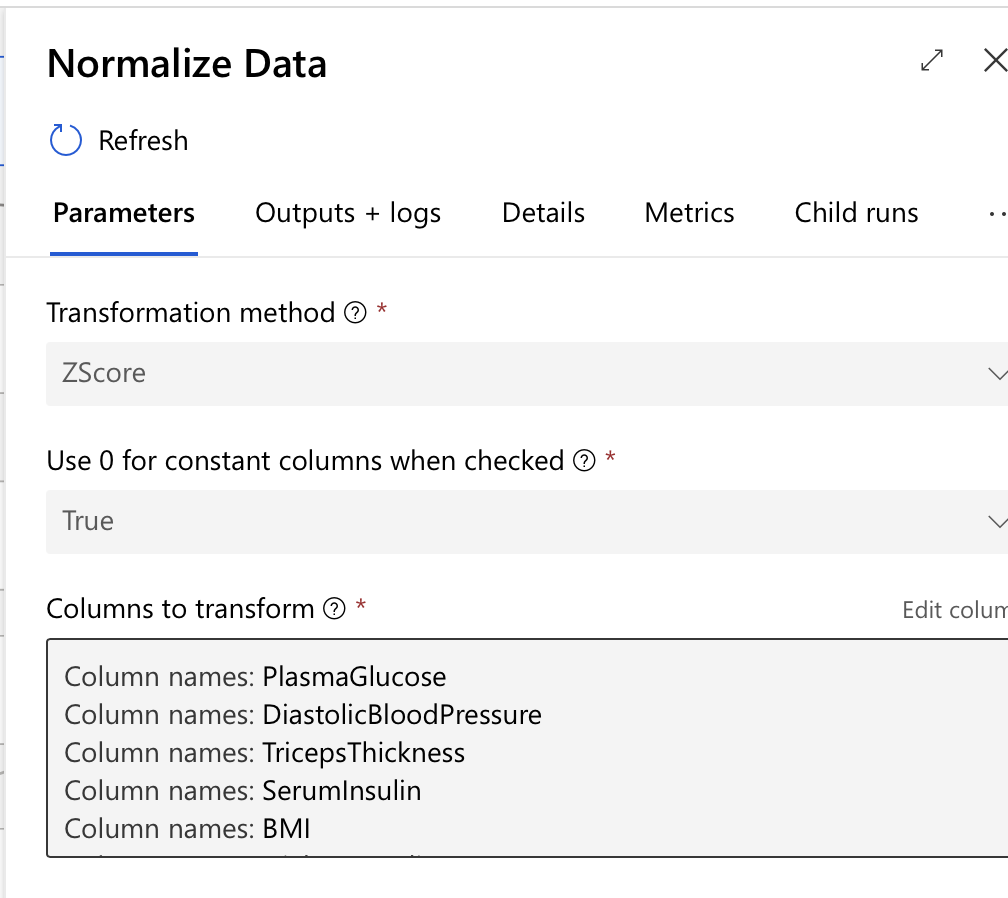
Step 2: Split the data.
I have split the data as 70% as train and 30% as test data.


Step 3: Train the model
Once you enter training the model in the pipeline, the model training begins.
Automated Explanation generation
A powerful feature of the ML designer is the explanation generator. You can turn this option by going into the Parameters setting, as shown in the screenshot below. So save compute resources, this is turned off by default and you would need to manually turn this on.


Once the Azure ML designer trains the model, using this feature, we generate the explanation to understand the context and better interpret the results. The below screenshot displays the explanation around the model’s performance and aggregate feature importance.

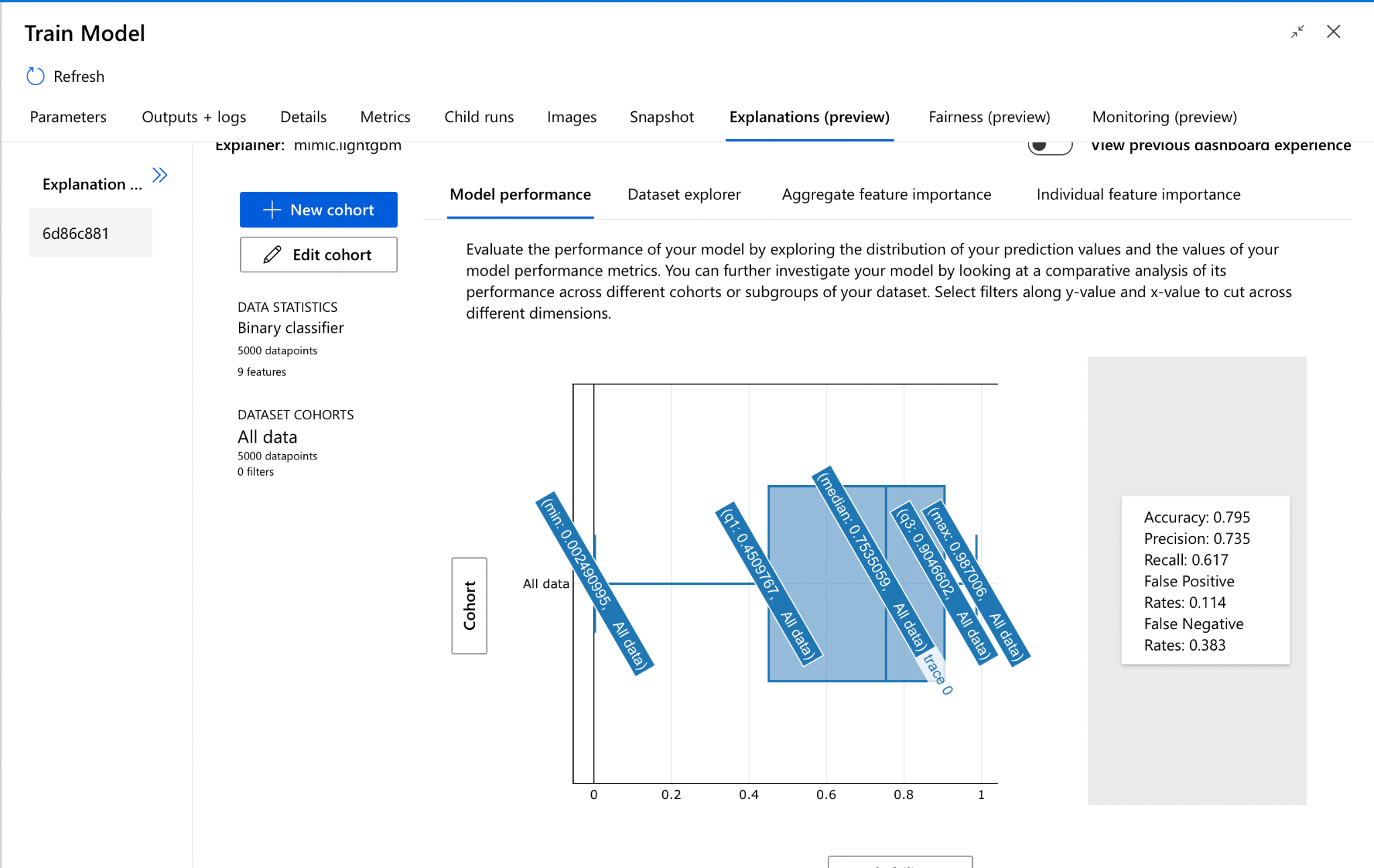
Figure: Explainer for Model performance

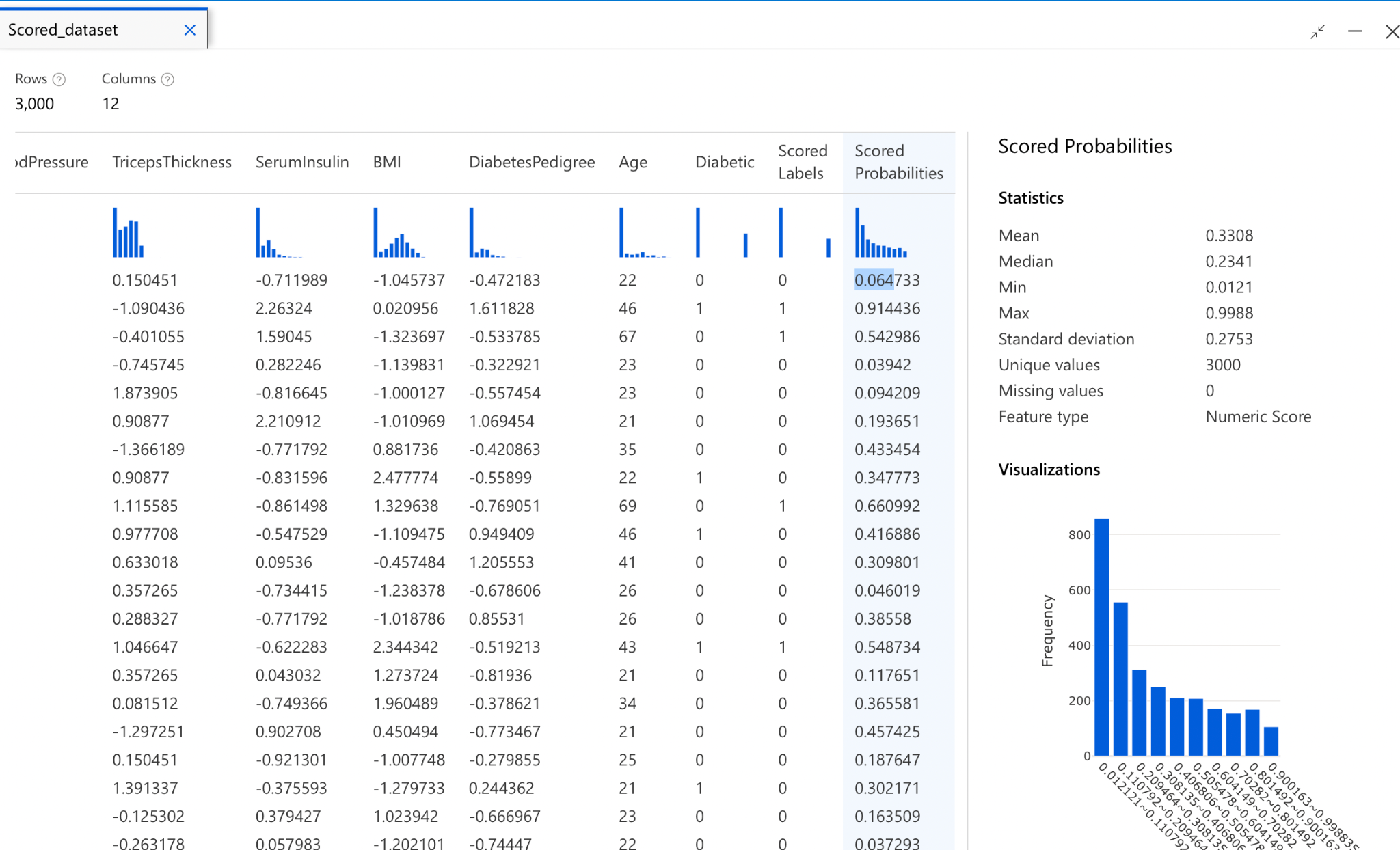
Step 4: Score the Model
In our case, the score will give us the prediction about the likelihood of a person getting diabetes.

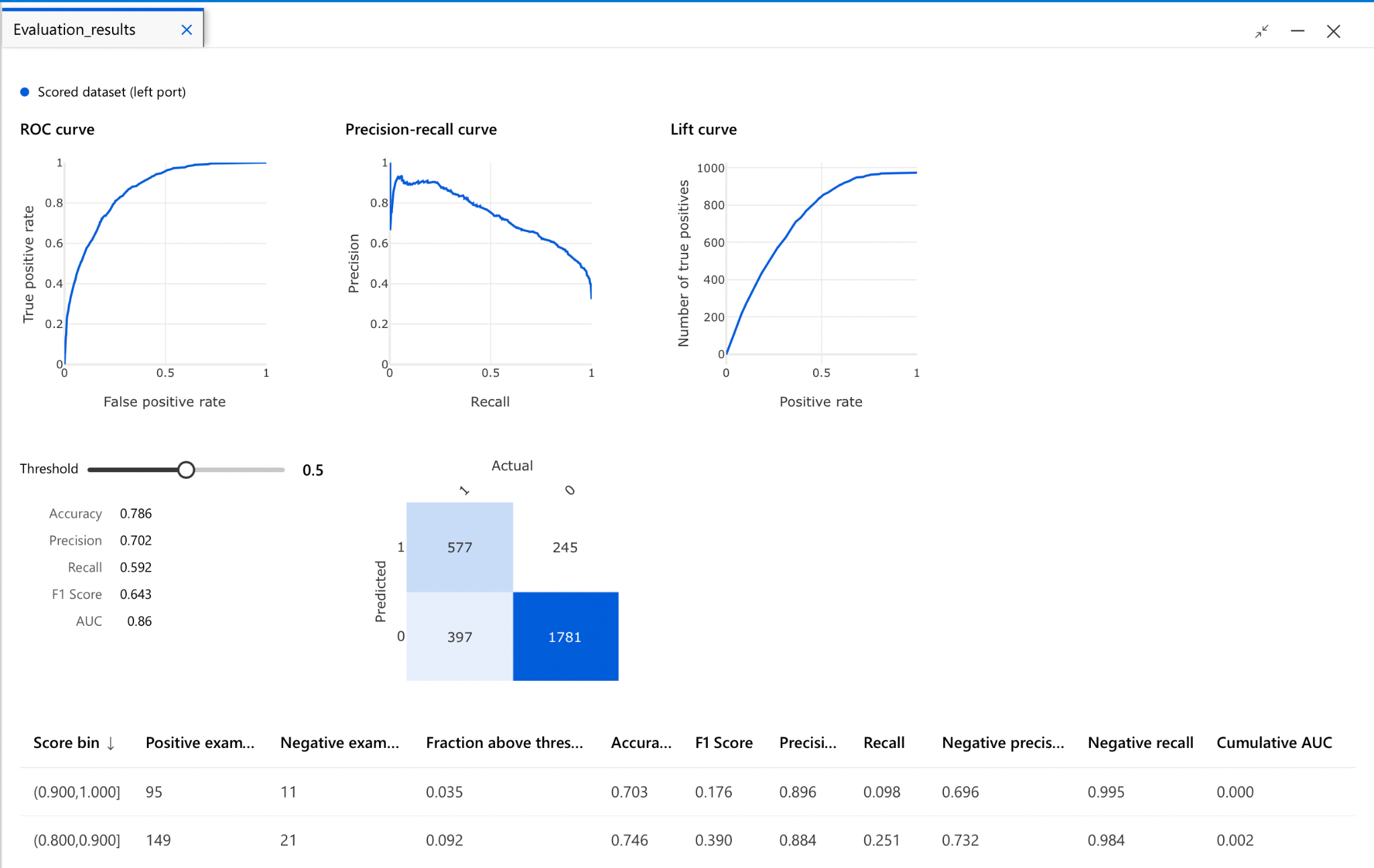
Step 5: Evaluate the model
The final step is to evaluate the model. We can evaluate the model using the following metrics


- ROC curve, precision-recall curve, lift curve.
- The confusion matrix tells us the ratios around true positives, false positives and helps us evaluate various metrics like sensitivity, specificity
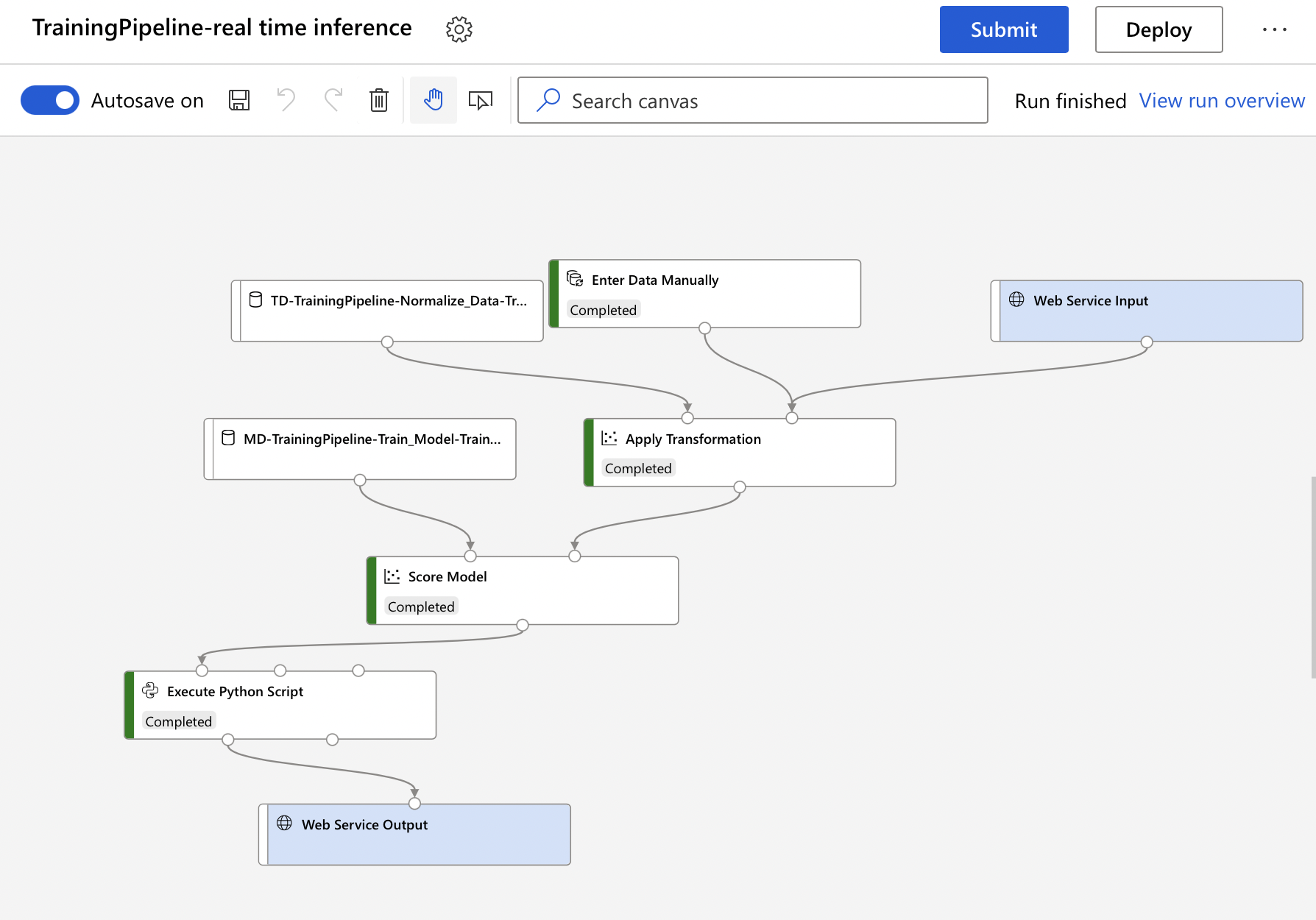
Inference pipeline: Using the model to predict
Once we train and evaluate the model using a training pipeline, we can use it to create an inference pipeline for batch prediction or a real-time inference pipeline. An inference pipeline encapsulates the trained model as a web service that predicts labels for new data.
Creating Inference Pipeline
You will get two options:
- Real-time inference Pipeline – Here we can make predictions in real-time with an immediate response from the service
- Batch inference Pipeline – Here the predictions are stored as files for business applications.


Once we create the inference pipeline, it looks like the picture below

Conclusion
As covered in detail in this guide, Azure has designed its machine learning services for all types of users and has built a strong ecosystem around them. From data ingestion to using the model as a service, to container orchestration, azure offers everything under one platform. Organizations, especially the ones who are already in the Azure ecosystem will find this indispensable in their machine learning journey.
Azure offers multiple ways to build and train models, while seamlessly taking care of the underlying infrastructure and heavy computing requirements. Whether you are a user who wants to unleash the power of machine learning without using code or a programmer using machine learning as part of a larger software, or a data scientist, you would feel delighted by the ease with which Azure ML orchestrates everything for you while being sensitive to your expertise.
References-
Images source: All images in this guide have been created by the author. Some images have been captured by the author while building the machine learning model.
Note: I have been certified as a Microsoft Certified Azure Data Scientist. Please connect with me on LinkedInThe media shown in this article are not owned by Analytics Vidhya and are used at the Author’s discretion